对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩充功能,并就能快速地处理多个文件。使用性能测试工具进行剖析,找到性能的困局并改进对代码进行质量剖析中国linux操作系统,清除所有警告设计10个测试样例用于测试,确保程序正常运行(比如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)使用Github进行代码管理撰写博客
基本功能
统计文件的字符数统计文件的词组总量统计文件的总行数统计文件中各词组的出现次数对给定文件夹及其递归子文件夹下的所有文件进行统计统计两个词组(短语)在一起的频度,输出频度最高的前10个。
功能模块
调用函数listDir,参数path为须要读取的路径,变量childpath为文件名
void listDir(char *path){ DIR *pDir=NULL; struct dirent *ent=NULL; int i=0; char childpath[512],ch; pDir=opendir(path); memset(childpath,0,sizeof(childpath)); while((ent=readdir(pDir))!=NULL){ if(ent->d_type & DT_DIR){ if(strcmp(ent->d_name,".")==0||strcmp(ent->d_name,"..")==0)continue; sprintf(childpath,"%s%s/",path,ent->d_name); listDir(childpath); } else{ sprintf(childpath,"%s%s",path,ent->d_name); puts(childpath); if((fin=fopen(childpath,"r"))==NULL){ fprintf(fout,"cannot open this filen"); exit(0); } while((ch=fgetc(fin))!=EOF){ if(ch>=32&&ch<=126){ //counting the number of character count_character++; } if(ch=='n'){ count_line++; } wordjudge(ch); } preword=NULL; wordstore[0]=wordstore[1]=''; count_line++; fclose(fin); } } }
调用函数wordjudge,对输入的字符判定其能够构成一个词组。若能,则将产生的字符进行下一步处理
void wordjudge(char ch){ int i; char dest[WORDLEN]={0}; if(ch>='A'&&ch<='Z'||ch>='a'&&ch<='z'||ch>='0'&&ch<='9'){ i=wordstore[0]; if(i<WORDLEN-2){ i=++wordstore[0]; wordstore[i]=ch; wordstore[i+1]=''; } else{ // printf("the word is too long!n"); } } else if(wordstore[0]) { for(i=1;i<=4&&wordstore[i]&&(wordstore[i]>='A'&&wordstore[i]<='Z'||wordstore[i]>='a'&&wordstore[i]<='z');i++); if(i==5){ strncpy(dest,wordstore+1,strlen(wordstore)-1); dest[strlen(dest)]=''; wordoperation(dest); count_word++; } wordstore[0]=0; wordstore[1]=''; } }
对要处理的词组进行标准化,对标准化后的词组哈希处理,存入词组结构体哈希表中。同时也顺带将当前词组和前一个词组组成的单词存入单词哈希表中
void wordoperation(char* newword){ int i,t,j,k,h=0,g=0; char c,newwordc[WORDLEN]; strcpy(newwordc,newword); t=(int)strlen(newword); c=*(newwordc+t-1); for(;c>='0'&&c<='9';t--){ newwordc[t]=''; c=*(newwordc+t-1); } strlwr(newwordc); /*The following centences are to store word*/ j=strlen(newwordc); for(k=1;k<j&&k<10;k++){ h=(newwordc[k-1]+(h*36))%WORDNUM; } while(Hashw[h].frequency&&strcmp(Hashw[h].after_deal,newwordc)){ h=(h+1)%WORDNUM; } if(Hashw[h].frequency){ Hashw[h].frequency ++; if(strncmp(Hashw[h].content ,newword,51)>0){ strcpy(Hashw[h].content ,newword); } } else{ Hashw[h].frequency =1; strcpy(Hashw[h].content,newword); strcpy(Hashw[h].after_deal ,newwordc); } /*The following centences are to store word group*/ if(preword){ for(i=0;i<4;i++){ g=(g*36+preword->after_deal[i])%GROUPNUM; } for(i=0;i<4;i++){ g=(g*36+newwordc[i])%GROUPNUM; } while(Hashg[g].frequency && (strncmp(Hashg[g].firstword->after_deal,preword->after_deal,51)||strncmp(Hashg[g].secword->after_deal,newwordc,51))){ g=(g+1)%GROUPNUM; } if(Hashg[g].frequency){ Hashg[g].frequency ++; } else{ Hashg[g].frequency =1; Hashg[g].firstword =preword; Hashg[g].secword =&Hashw[h]; } } preword=&Hashw[h]; }
遍历哈希表,找出前十词组和单词
void toptenw(void){ word tenw[10]={0}; int j,m,n; for(j=0;j<WORDNUM;j++){ if(Hashw[j].frequency ){ for(m=9;m>=0&&(!tenw[m].frequency||Hashw[j].frequency>tenw[m].frequency);m--); if(m+1<=9){ for(n=9;n>m+1;n--){ tenw[n]=tenw[n-1]; } tenw[m+1]=Hashw[j]; } } } for(j=0;j<10;j++){ if(tenw[j].frequency)fprintf(fout,"%s: %dn",tenw[j].content,tenw[j].frequency); } } void topteng(void){ wordgroup teng[10]={0}; long int j,m,n; for(j=0;j<GROUPNUM;j++){ if(Hashg[j].frequency ){ for(m=9;m>=0&&(!teng[m].frequency||Hashg[j].frequency>teng[m].frequency);m--); if(m+1<=9){ for(n=9;n>m+1;n--){ teng[n]=teng[n-1]; } teng[m+1]=Hashg[j]; } } } for(j=0;j<10;j++){ if(teng[j].frequency)fprintf(fout,"%s %s: %dn",teng[j].firstword->content,teng[j].secword->content,teng[j].frequency); } }
性能剖析
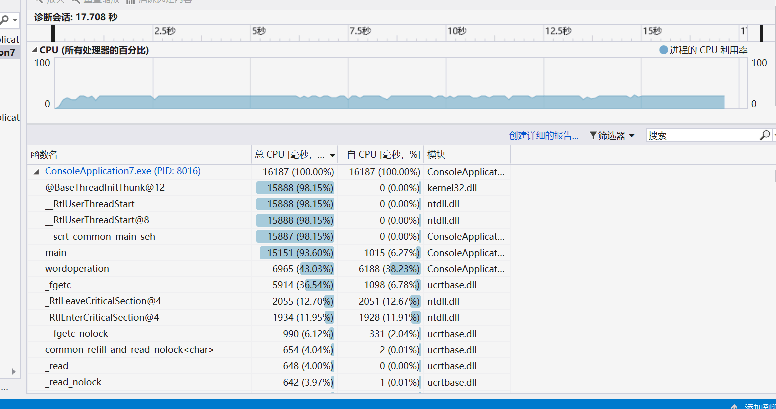
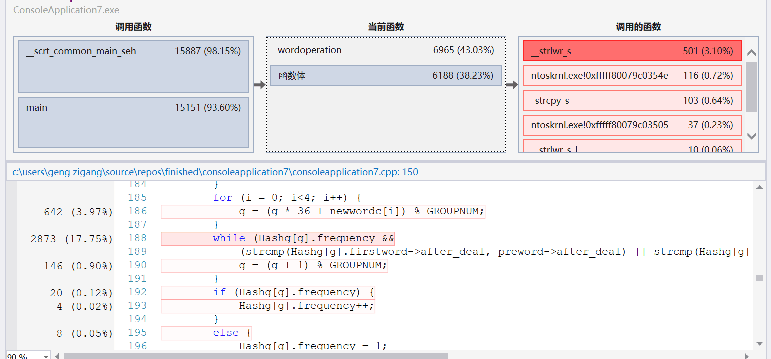
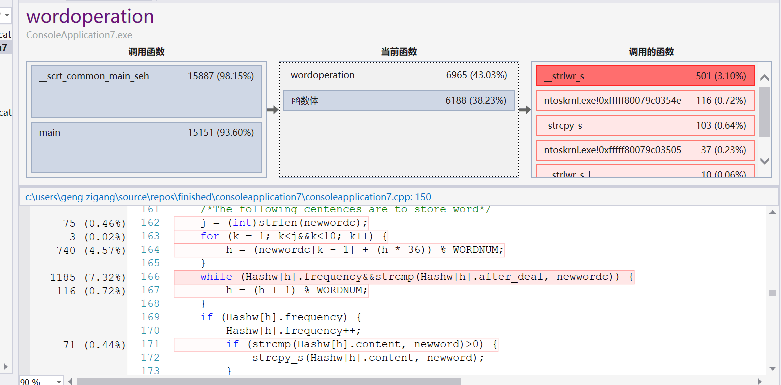
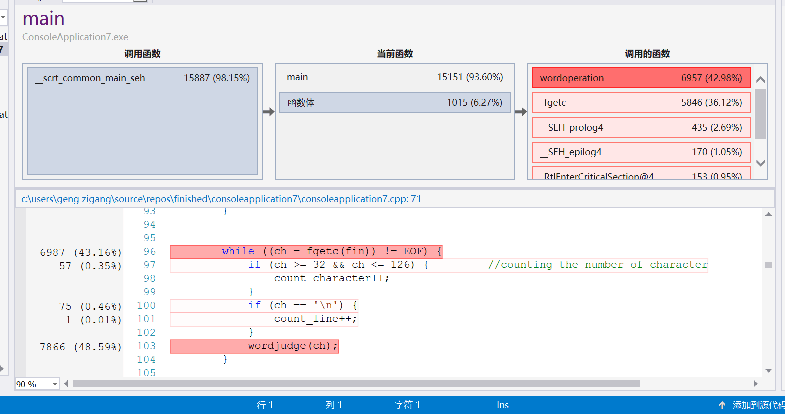
release模式下运行时间大约16s左右,可以看见:

fgetc历时量巨大,而且读字符是必不可少的操作所以不好更改。对每一个字符判定处理的函数wordjudge调用次数也好多,而且要处理多少字符就要调用,多少次函数,所以也没有太多优化空间。对单词和词的存入判定占用也较大,而且也是情理之中。遍历单词和词哈希表找前十倒是没有花多少时间。为了提高时间效率,开了较大的空间,属于时间和空间的互换。
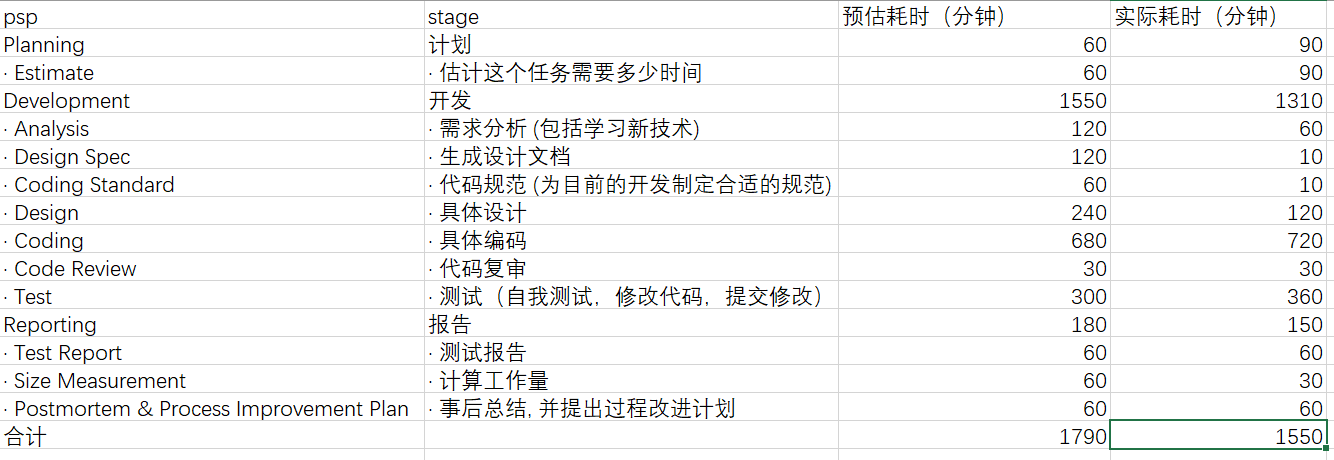
PSP表格
测试结果
VS下(左助教右我的)
Linux下(左我的右助教)
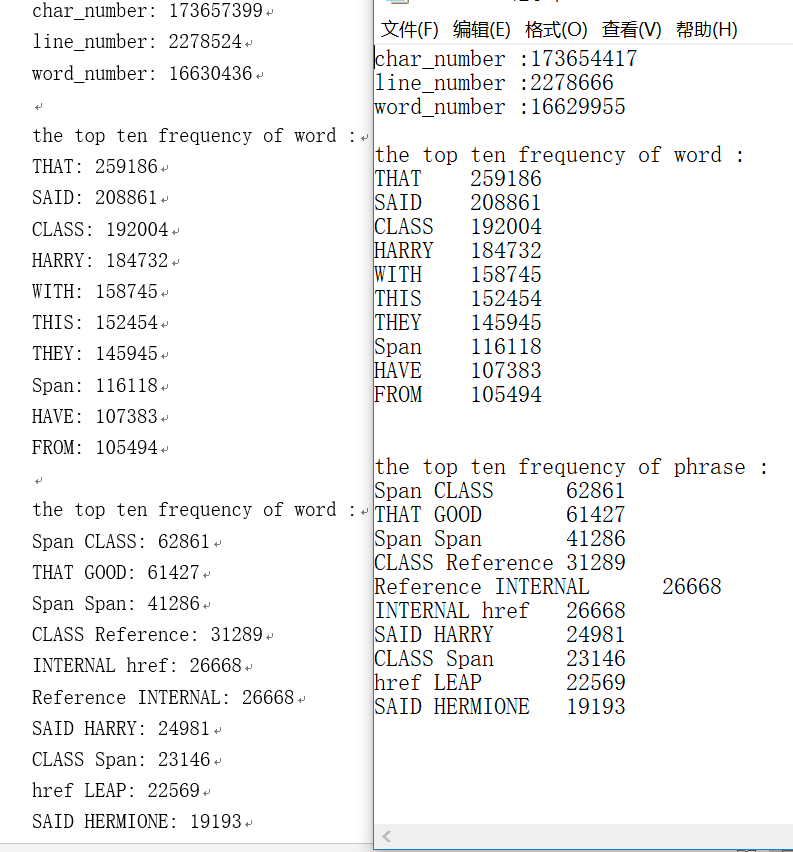
可以见到,在两种测试环境下,前十词组和单词都和助教都是一样的。并且两种环境下的词组字符和行数都有数百的偏差,实在不是很清楚缘由。
项目经历及总结剖析
一开始我的畏难情绪非常严重linux获取当前时间,由于自己实在比较菜linux下c统计文件词频,不仅c和dev啥也没用过,所以这礼拜的任务实在太多。所以我选择先写完其它作业再竭力肝软工。觉得这个决定很正确。由于我在构思的时侯也确实收到了一些写了博客的朋友的启发。本次作业,周五周六写完基本函数模块,周日一轮测试,发觉不行并进行了大的解构。周六晚上完成VS上的调试,周四晚10点完成Linux下的移植。一开始词和短语的哈希表是26*26*26*26的字段,根据前4个字母排序。因为这些方法和题目要求契合的较好,我一度认为这是挺好的解决方案。并且运行到大文件的时侯还是出现了读取特别慢的情况。几经考虑后决定加强字段容量,并优化单词的储存形式和哈希函数,使程序显著清晰了不少,速率和稳定性都有提高。此次个人作业让我了解了VS的一些基本操作linux下c统计文件词频,以及使用GitHub,遍历文件夹,以及Linux的一些简单命令和操作,还有关于程序移植方面的知识,以及练习了一些调试的技能,可以说是逼着狠狠恶补了一把。此次软工还我明白了时间分配的重要性,从周四仍然肝到周日,欠下了一堆的作业,上课的状态也不是挺好,然后又要花很多时间来补,并且马上期中考又要加实验课,实在好惨。之后要么更新技能,提升水平,要么“有舍才有得”/无奈。





