算法的重要性,我就不多说了吧,想去大厂linux下c统计文件词频,就必需要经过基础知识和业务逻辑笔试+算法笔试。所以,为了提升你们的算法能力红旗linux,这个公众号后续每晚带你们做一道算法题,题目就从LeetCode里面选!
明天和你们聊的问题称作统计词频linux操作系统培训,我们先来看题面:
Writeabashscripttocalculatethefrequencyofeachwordinatextfilewords.txt.
题意
写一个bash脚本以统计一个文本文件words.txt中每位词组出现的频度。
为了简单起见,你可以假定:
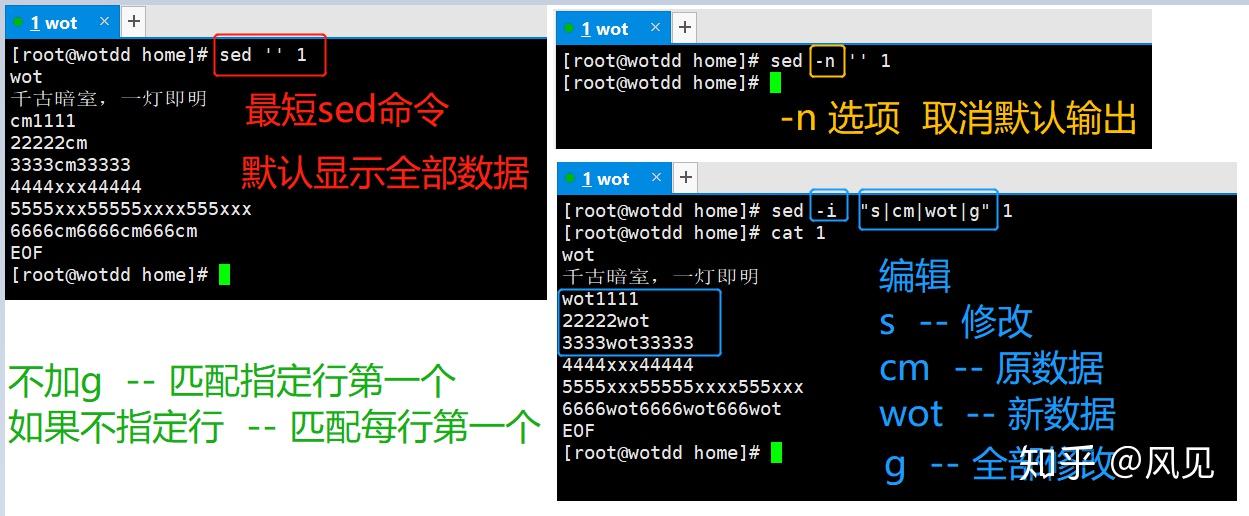
示例
假设 words.txt 内容如下:
the day is sunny the the
the sunny is is
你的脚本应当输出(以词频降序排列):
the 4
is 3
sunny 2
day 1
说明:
不要担心词频相同的单词的排序问题,每个单词出现的频率都是唯一的。
你可以使用一行 Unix pipes 实现吗?复制
解题思路:cat+tr+sort+uniq+sort+awk
cat命令:用于联接文件并复印到标准输出设备上。
tr命令:用于转换或删掉文件中的字符,其中的-s选项表示--squeeze-repeats,即削减连续重复的字符成指定的单个字符。

sort命令:用于将文本文件内容加以排序,其中-r参数表示以相反的次序来排序linux下c统计文件词频,本题中即升序。
uniq命令:用于删掉文件中的重复行,其中-c选项表示在输出行后面加上每行在输入文件中出现的次数。
awk命令:AWK是一种处理文本文件的语言,是一个强悍的文本剖析工具。下列脚本中awk命令的用法表示每行按空格或TAB分割,输出文本中的第2、1项。

cat words.txt | tr -s ' ' 'n' | sort | uniq -c | sort -r | awk '{ print $2, $1 }'复制
好了,明天的文章就到这儿,假如认为有所收获,请顺手点个在看或则转发吧,大家的支持是我最大的动力。





