因为日志本身固有的特点,记录从左往右开始次序插入,也就意味着左侧的记录相较于右侧的记录“更老”,也就是说我们可以不用依赖于系统时钟,这个特点对于分布式系统来说相当重要。
日志在数据库中的应用
日志是哪些时侯出现早已无从得悉,可能是概念上来讲太简单。在数据库领域中韩志更多的是用于在系统crash的时侯同步数据以及索引等,比如MySQL中的redolog,redolog是一种基于c盘的数据结构,用于在系统死掉的时侯保证数据的正确性、完整性,也叫预写日志,比如在一个事物的执行过程中,首先会写redolog,之后才能应用实际的修改,这样当系统crash后恢复时就才能依据redolog进行重放因而恢复数据(在初始化的过程中,这个时侯不会还没有顾客端的联接)。日志也可以用于数据库主从之间的同步,由于本质上,数据库所有的操作记录都早已写入到了日志中,我们只要将日志同步到slave,并在slave重放就能否实现主从同步,这儿也可以实现好多其他须要的组件,我们可以通过订阅redolog因而领到数据库所有的变更,进而实现个性化的业务逻辑,比如审计、缓存同步等等。
日志在分布式系统中的应用
分布式系统服务本质上就是关于状态的变更,这儿可以理解为状态机,两个独立的进程(不依赖于外部环境,比如系统时钟、外部插口等)给定一致的输入将会形成一致的输出并最终保持一致的状态,而日志因为其固有的次序性并不依赖系统时钟,刚好可以拿来解决变更有序性的问题。
我们借助这个特点实现解决分布式系统中遇见的好多问题。诸如RocketMQ中的备节点linux系统日志文件deepin linux,主broker接收顾客端的恳求,并记录日志,之后实时同步到salve中,slave在本地重放,当master死掉的时侯,slave可以继续处理恳求,比如拒绝写恳求并继续处理读恳求。日志中不仅仅可以记录数据,也可以直接记录操作,比如SQL句子。
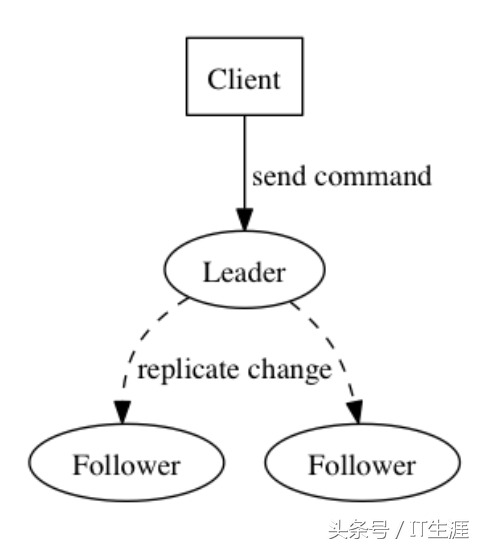
日志是解决一致性问题的关键数据结构,日志如同是操作序列,每一条记录代表一条指令,比如应用广泛的Paxos、Raft合同,都是基于日志建立上去的一致性合同。
日志在MessageQueue中的应用
日志可以很便捷的用于处理数据之间的流入流出,每一个数据源都可以形成自己的日志,这儿数据源可以来自各个方面,比如某个风波流(页面点击、缓存刷新提醒、数据库binlog变更),我们可以将日志集中储存到一个集群中,订阅者可以依据offset来读取日志的每条记录,按照每条记录中的数据、操作应用自己的变更。
这儿的日志可以理解为消息队列,消息队列可以起到异步前馈、限流的作用。为何说前馈呢?由于对于消费者、生产者来说,两个角色的职责都很清晰,就负责生产消息、消费消息,而不用关心下游、上游是谁,不管是来数据库的变更日志、某个风波也好,对于某一方来说我根本不须要关心,我只须要关注自己感兴趣的日志以及日志中的每条记录。
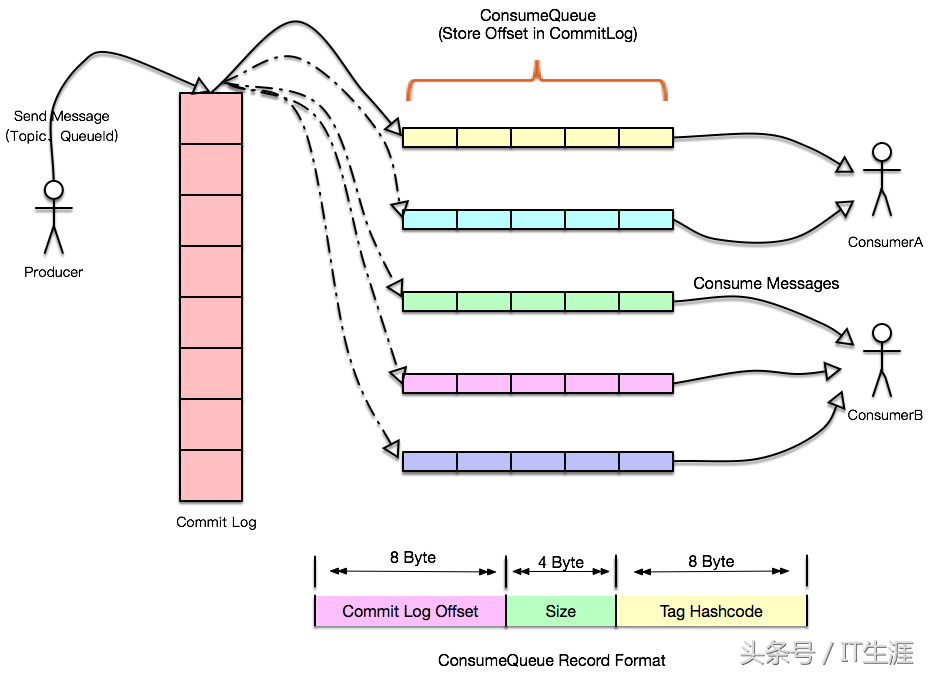
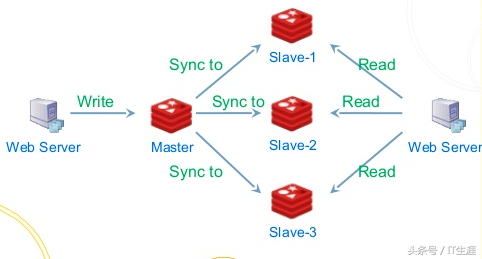
我们晓得数据库的QPS是一定的,而下层应用通常可以纵向扩容,这个时侯假如到了双十一这些恳求忽然的场景,数据库会吃不消,这么我们就可以引入消息队列,将每位队数据库的操作讲到日志中,由另外一个应用专门负责消费这种日志记录并应用到数据库中,但是即使数据库挂了,当恢复的时侯也可以从先前消息的位置继续处理(RocketMQ和Kafka都支持ExactlyOnce语义),这儿虽然生产者的速率异于消费者的速率也不会有影响,日志在这儿起到了缓冲的作用,它可以将所有的记录储存到日志中,并定时同步到slave节点,这样消息的积压能力才能得到挺好的提高,由于写日志都是有master节点处理,读恳求这儿分为两种,一种是tail-read,就是说消费速率才能跟得上写入速率的,这些读可以直接走缓存,而另一种也就是落后于写入恳求的消费者,这些可以从slave节点读取,这样通过IO隔离以及操作系统自带的一些文件策略,比如pagecache、缓存预读等,性能可以得到很大的提高。
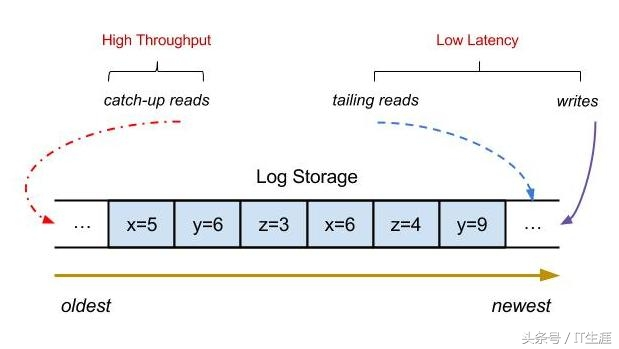
分布式系统中可纵向扩充是一个相当重要的特点,加机器能解决的问题都不是问题。这么怎样实现一个就能实现纵向扩充的消息队列呢?如果我们有一个单机的消息队列linux文本编辑器,随着topic数量的上升,IO、CPU、带宽等就会渐渐成为困局,性能会渐渐增长,这么这儿怎样进行性能优化呢?
topic/日志分片,本质上topic写入的消息就是日志的记录,这么随着写入的数目越多,单机会渐渐的成为困局,这个时侯我们可以将单个topic分为多个子topic,并将每位topic分配到不同的机器上,通过这些方法,对于这些消息量极大的topic就可以通过加机器解决,而对于一些消息量较少的可以分到到同一台机器或不进行分区
groupcommit,比如Kafka的producer顾客端linux系统日志文件,写入消息的时侯,是先写入一个本地显存队列,之后将消息根据每位分区、节点汇总,进行批量递交,对于服务器端或则broker端,也可以借助这些方法,先写入pagecache,再定时刷盘,刷盘的方法可以依据业务决定,比如金融业务可能会采取同步刷盘的形式。
规避无用的数据拷贝
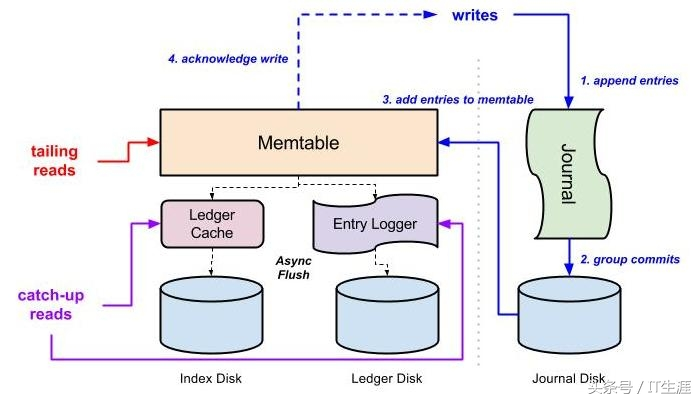
IO隔离
日志在分布式系统中饰演了很重要的角色,是理解分布式系统各个组件的关键,随着理解的深入,我们发觉好多分布式中间件都是基于日志进行完善的,比如Zookeeper、HDFS、Kafka、RocketMQ、GoogleSpanner等等,甚至于数据库,比如Redis、MySQL等等,其master-slave都是基于日志同步的方法,依赖共享的日志系统,我们可以实现好多系统:节点间数据同步、并发更新数据次序问题(一致性问题)、持久性(系统crash时才能通过其他节点继续提供服务)、分布式锁服务等等,相信渐渐的通过实践、以及大量的论文阅读过后,一定会有更深层次的理解。





