有关linux下进程与线程看过好多文章,我觉的这篇可以说最精典一.基础知识:线程和进程根据教科书上的定义,进程是资源管理的最小单位,线程是程序执行的最小单位。在操作系统设计上,从进程演变出线程,最主要的目的就是更好的支持SMP以及降低(进程/线程)上下文切换花销。无论根据如何的分法,一个进程起码须要一个线程作为它的指令执行体,进程管理着资源(例如cpu、内存、文件等等),而将线程分配到某个cpu上执行。一个进程其实可以拥有多个线程,此时,假如进程运行在SMP机器上,它就可以同时使用多个cpu来执行各个线程,达到最大程度的并行,以提升效率;同时,即cpu的机器上,采用多线程模型来设计程序,正如当初采用多进程模型取代单进程模型一样,使设计更简练、功能更完备,程序的执行效率也更高,比如采用多个线程响应多个输入,而此时多线程模型所实现的功能实际上也可以用多进程模型来实现,而与前者相比,线程的上下文切换开支就比进程要小多了,从语义上来说,同时响应多个输入这样的功能,实际上就是共享了除cpu以外的所有资源的。针对线程模型的两大意义,分别开发出了核心级线程和用户级线程两种线程模型linux vi 命令,分类的标准主要是线程的调度者在核内还是在核外。
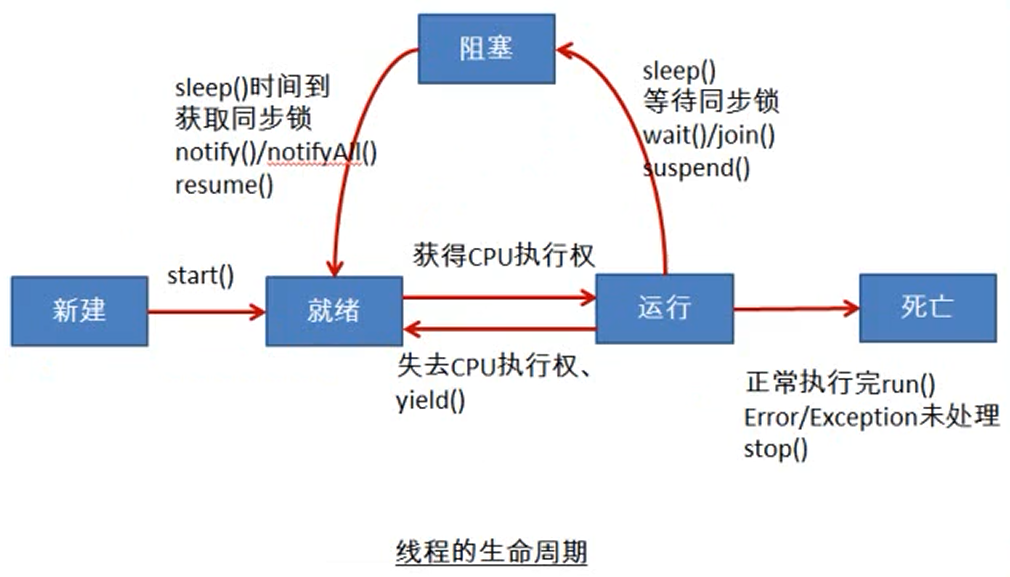
后者更利于并发使用多处理器的资源,而前者则更多考虑的是上下文切换花销。在目前的商用系统中,一般都将二者结合上去使用,既提供核心线程以满足smp系统的须要,也支持用线程库的形式在用户态实现另一套线程机制,此时一个核心线程同时成为多个用户态线程的调度者。正如好多技术一样linux进程线程,"混和"一般都能带来更高的效率,但同时也带来更大的实现难度,出于"简单"的设计思路linux系统界面,Linux从一开始就没有实现混和模型的计划,但它在实现上采用了另一种思路的"混和"。在线程机制的具体实现上,可以在操作系统内核上实现线程,也可以在核外实现,前者似乎要求核内起码实现了进程,而后者则通常要求在核内同时也支持进程。核心级线程模型其实要求后者的支持,而用户级线程模型则不一定基于前者实现。这些差别,正如前所述,是两种分类方法的标准不同带来的。当核内既支持进程也支持线程时,就可以实现线程-进程的"多对多"模型,即一个进程的某个线程由核内调度,而同时它也可以作为用户级线程池的调度者,选择合适的用户级线程在其空间中运行。这就是上面提及的"混和"线程模型,既可满足多处理机系统的须要,也可以最大限度的减少调度开支。绝大多数商业操作系统(如DigitalUnix、Solaris、Irix)都采用的这些才能完全实现POSIX1003.1c准的线程模型。
在核外实现的线程又可以分为"一对一"、"多对一"两种模型,后者用一个核心进程(其实是轻量进程)对应一个线程,将线程调度等同于进程调度,交给核心完成,而前者则完全在核外实现多线程,调度也在用户态完成。前者就是上面提及的单纯的用户级线程模型的实现方法,其实,这些核外的线程调度器实际上只须要完成线程运行栈的切换,调度开支十分小,但同时由于核心讯号(无论是同步的还是异步的)都是以进程为单位的,因此难以定位到线程,所以这些实现方法不能用于多处理器系统,而这个需求正显得越来越大,因而,在现实中,纯用户级线程的实现,除算法研究目的以外,几乎早已消失了。Linux内核只提供了轻量进程的支持,限制了更高效的线程模型的实现,但Linux注重优化了进程的调度开支,一定程度上也填补了这一缺陷。目前最流行的线程机制LinuxThreads所采用的就是线程-进程"一对一"模型,调度交给核心,而在用户级实现一个包括讯号处理在内的线程管理机制。Linux-LinuxThreads的运行机制正是本文的描述重点。二.Linux2.4内核中的轻量进程实现最初的进程定义都包含程序、资源及其执行三部份,其中程序一般指代码,资源在操作系统层面上一般包括显存资源、IO资源、信号处理等部份,而程序的执行一般理解为执行上下文,包括对cpu的占用,后来发展为线程。
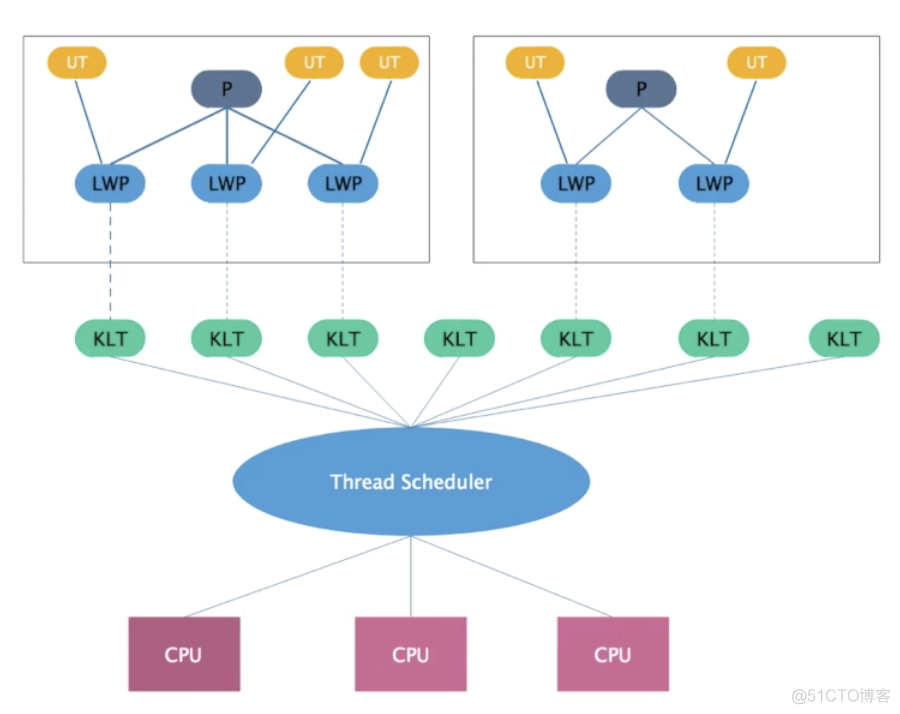
在线程概念出现曾经,为了降低进程切换的开支,操作系统设计者逐步修正进程的概念,逐步准许将进程所占有的资源从其主体剥离下来,容许个别进程共享一部份资源,比如文件、信号,数据显存,甚至代码,这就发展出轻量进程的概念。Linux内核在2.0.x版本就早已实现了轻量进程,应用程序可以通过一个统一的clone()系统调用插口,用不同的参数指定创建轻量进程还是普通进程。在内核中,clone()调用经过参数传递和解释后会调用do_fork(),这个核内函数同时也是fork()、vfork()系统调用的最终实现:linux-2.4.20/kernel/fork.cintdo_fork(unsignedlongclone_flags,unsignedlongstack_start,structpt_regs*regs,unsignedlongstack_size)其中的clone_flags取自以下宏的"或"值:linux-2.4.20/include/linux/sched.h#defineCSIGNAL0x000000ffsignalmask#defineCLONE_VM0x00000100VMsharedbetweenprocesses#defineCLONE_FS0x00000200fsinfosharedbetweenprocesses#defineCLONE_FILES0x00000400openfilessharedbetweenprocesses#defineCLONE_SIGHAND0x00000800signalhandlersblockedsignalsshared#defineCLONE_PID0x00001000pidshared#defineCLONE_PTRACE0x00002000wewantlettracingcontinuechildtoo#defineCLONE_VFORK0x00004000parentwants#defineCLONE_PARENT0x00008000wewantsameparent#defineCLONE_THREAD0x00010000Samethreadgroup?#defineCLONE_NEWNS0x00020000Newnamespacegroup?#defineCLONE_SIGNAL(CLONE_SIGHANDCLONE_THREAD)在do_fork()中,不同的clone_flags将造成不同的行为,对于LinuxThreads,它使用(CLONE_VMCLONE_SIGHAND)参数来调用clone()创建"线程",表示共享显存、共享文件系统访问计数、共享文件描述符表,以及共享讯号处理方法。
本节就针对这几个参数,瞧瞧Linux内核是怎样实现这种资源的共享的。1.CLONE_VMdo_fork()须要调用copy_mm()来设置task_struct中的mm和active_mm项,这两个mm_struct数据与进程所关联的显存空间相对应。假如do_fork()时指定了CLONE_VM开关,copy_mm()将把新的task_struct中的mm和active_mm设置成与current的相同,同时提升该mm_struct的使用者数量(mm_struct::mm_users)。也就是说,轻量级进程与父进程共享显存地址空间,由右图示意可以看出mm_struct在进程中的地位:2.CLONE_FStask_struct中借助fs(structfs_struct*)记录了进程所在文件系统的根目录和当前目录信息,do_fork()时调用copy_fs()复制了这个结构;而对于轻量级进程则仅增加fs-count计数linux进程线程,与父进程共享相同的fs_struct。也就是说,轻量级进程没有独立的文件系统相关的信息,进程中任何一个线程改变当前目录、根目录等信息都将直接影响到其他线程。
3.CLONE_FILES一个进程可能打开了一些文件,在进程结构task_struct中借助files(structfiles_struct*)来保存进程打开的文件结构(structfile)信息,do_fork()中调用了copy_files()来处理这个进程属性;轻量级进程与父进程是共享该结构的,copy_files()时仅降低files-count计数。这一共享致使任何线程都能访问进程所维护的打开文件,对它们的操作会直接反映到进程中的其他线程。4.CLONE_SIGHAND每一个Linux进程都可以自行定义对讯号的处理方法,在task_structsig(structsignal_struct)中使用一个structk_sigaction结构的链表来保存这个配置信息,do_fork()中的copy_sighand()负责复制该信息;轻量级进程不进行复制,而仅仅降低signal_struct::count计数,与父进程共享该结构。也就是说,子进程与父进程的讯号处理方法完全相同,但是可以互相修改。do_fork()中所做的工作好多,在此不详尽描述。
对于SMP系统,所有的进程fork下来后,都被分配到与父进程相同的cpu上,仍然到该进程被调度时才能进行cpu选择。虽然Linux支持轻量级进程,但并不能说它就支持核心级线程,由于Linux程"和"进程"实际上处于一个调度层次,共享一个进程标示符空间,这些限制致使不可能在Linux上实现完全意义上的POSIX线程机制,因而诸多的Linux线程库实现尝试都只能尽可能实现POSIX的绝大部份语义,并在功能上尽可能迫近。三.LinuxThread的线程机制LinuxThreadsXavierLeroy(Xavier.Leroy@inria.fr)负责开发完成,并已绑定在GLIBC中发行。它所实现的就是基于核心轻量级进程的"一对一"线程模型,一个线程实体对应一个核心轻量级进程,而线程之间的管理在核外函数库中实现。1.线程描述数据结构及实现限制LinuxThreads定义了一个struct_pthread_descr_struct数据结构来描述线程,并使用全局字段变量__pthread_handles来描述和引用进程所辖线程。在__pthread_handles中的前两项,LinuxThreads定义了两个全局的系统线程:__pthread_initial_thread和__pthread_manager_thread,并用__pthread_main_thread





