序言
每位在Linux环境下工作的程序员,都碰到过段错误(segmentationfault)。所谓段错误,本质上是程序访问了非法显存地址而导致的一种错误类型。
造成程序访问非法地址的缘由有好多,如野表针、内存被踩、栈溢出、访问没有权限的显存等。
之前更新调试专题文章时,有同事问到段错误的调试方式,我承诺会更新文章专门介绍,本文就是来填这个坑的。
本文将介绍9种十分实用的段错误调试方式。
1.日志
日志是一种十分实用的调试手段,我们可以从系统日志中获得好多特别有用的信息,因而反推问题出现的前后系统中到底发生了哪些异常状况。
printf可能是最简单的日志记录方式,你们都懂的,不再赘言。
2.GDB
GDB的强悍无需多言,对于段错误,借助GDB很容易能够定位到触发问题的那一行代码。如右图示例代码:

编译时加上-g选项:
gcc -g segfault.c -o segfault在GDB中运行程序:
段错误触发时,GDB会直接告诉我们问题出现在哪一行代码,而且可以借助backtrace命令查看完整调用栈信息。据悉,还可以借助其他常规调试命令来查看参数、变量、内存等数据。
这些方法似乎十分有效,但好多时侯,问题并不是100%必现的,我们不可能仍然把程序运行在GDB中,这对程序的执行性能等会有很大的影响。
这时,我们可以让程序在异常中止时生成coredump文件,之后用调试工具对它进行离线调试。
3.CoreDump+GDB
Coredump是Linux提供的一种特别实用的程序调试手段linux内核打印调用栈,在程序异常中止时,Linux会把程序的上下文信息记录在一个core文件中,之后可以借助GDB等调试工具对core文件进行离线调试。
好多系统中,按照默认配置,程序异常退出时不会形成coredump文件。可以通过下边这条命令查看:
ulimit -c假如值是0,则默认不会形成coredump文件。可以用下边命令设置生成coredump文件的大小:
ulimit -c 10240里面命令把coredump文件大小设置为10MB。假如储存空间不受限的话,可以直接取消大小限制:
ulimit -c unlimited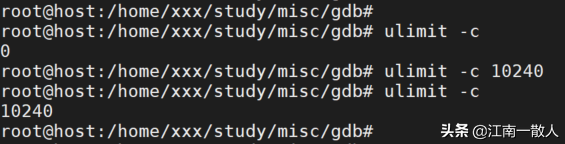
设置coredump文件大小
之后重新运行示例程序,段错误触发后,默认会在当前目录下生产一个core文件:
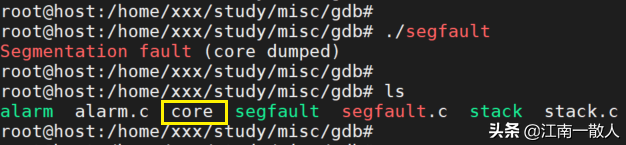
之后用GDB加载调试core文件。调试时,不仅coredump文件外,GDB还须要从可执行文件中加载调试信息。
gdb segfault core结果如右图:
GDB调试coredump
与直接在GDB运行程序类似,coredump文件加载上去以后,GDB会直接显示触发问题的那一行代码,也可以使用backtrace、print等常规命令从coredump文件中获取信息。
在大多数系统中,这些coredump+GDB的手段十分有效,但是应当优先考虑使用。
并且有时侯,因为某种缘由,系统可能难以生存coredump文件。例如出于安全考虑,coredump功能可能是被彻底严禁的,或则在一些储存空间受限的嵌入式系统中,也难以生成coredump文件。
此时,我们就不得不考虑其它的调试手段了。
4.signalcapture+backtrace
4.1段错误在Linux系统上的处理过程
在Linux系统中,程序访问非法地址时,会被CPU捕获后触发硬件异常处理机制,并通知Linuxkernel程序运行出现异常,kernel会对各类异常进行分辨,之后向应用程序发送不同的signal,由应用程序自己进行故障恢复处理。
对于访问非法地址造成的段错误,Linuxkernel会向应用程序发送11号signal,也就是SIGSEGV讯号,该讯号的默认处理是中止程序运行。
我们可以注册一个讯号处理函数,当接受到Linuxkernel发送过来的SIGSEGV讯号后,在讯号处理函数中把当前程序的上下文信息记录出来,方面后续问题定位。
4.2两个有用的函数
int backtrace(void **buffer, int size);
void backtrace_symbols_fd(void *const *buffer, int size, int fd);backtrace获取程序的调用栈地址信息,并储存在buffer指定的一个链表中,链表大小为size。
backtrace_symbols_fd按照backtrace得到的调用栈地址数据,获取地址对应的符号信息,并把结果讲到fd指定的文件中。
4.3示例
对前面的示例做下更改,降低一个讯号处理函数,如右图所示:
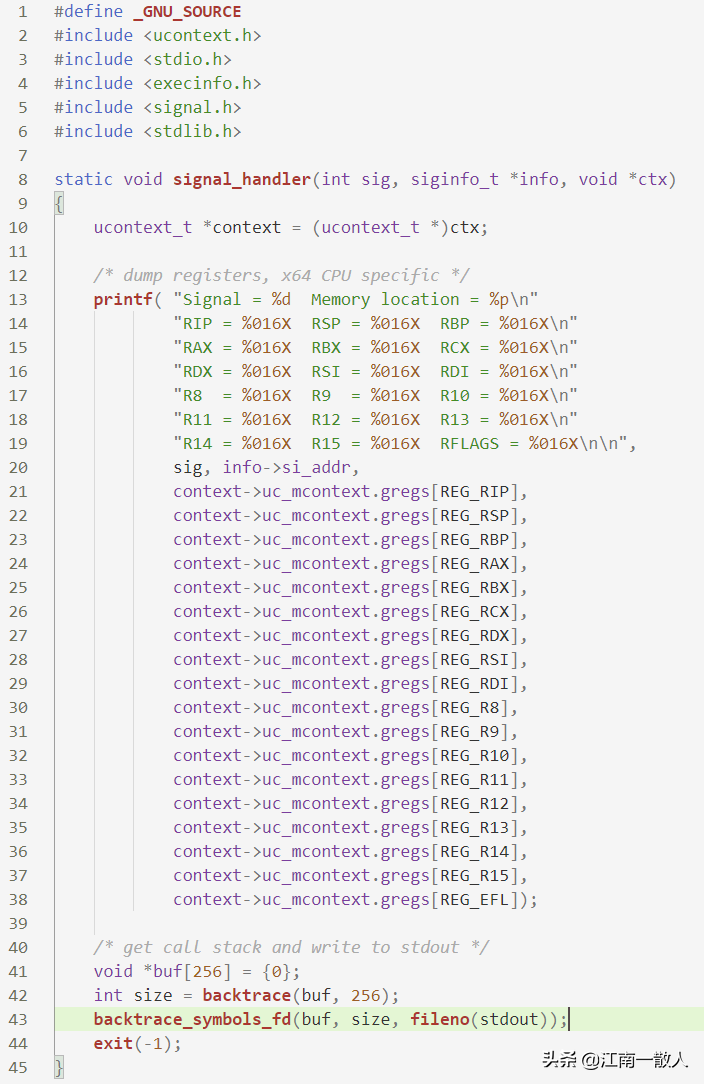
讯号处理函数
在讯号处理函数signal_handler中,先把寄存器信息复印下来linux内核打印调用栈,之后用backtrace和backtrace_symbols_fd获取调用栈信息,并写入stdout。
之后,在main函数中注册SIGSEGV的讯号处理函数,如右图:

注册讯号处理函数
编译一下:
gcc -rdynamic segfault.c -o segfault看下运行结果:
运行结果
为了便捷演示,示例中的讯号处理函数只记录了寄存器和调用栈信息,实际项目中按照需求,可以同时记录其它重要信息,如stackdump、全局变量、数据段dump等。
有两点须要注意:
示例讯号处理函数中复印寄存器的部份是针对x64CPU的,其它CPU请参考sys/ucontext.h文件中对mcontext_t的定义。编译时须要加上-rdynamic选项,否则backtrace_symbols_fd未能正确获取符号信息。5.signalcapture+GDB
有些问题很难再现,直接在GDB里运行调试的话,可能要浪费好多时间去不停的尝试再现它。
那有没有一种方法,可以让问题再现时手动启动GDB呢?其实有!
与前面的一种方式类似,我们一直借助signalcapture的形式。只不过,在讯号处理函数中,我们不再使用backtrace获取调用栈信息,而是直接启动GDB:
对讯号处理函数作一些更改,如右图:

原理很简单,就是段错误发生时,在SIGSEGV讯号处理函数中执行命令:
gdb --pid=xxx -ex bt -q启动GDB,并attach到当前进程,之后执行backtrace命令复印调用栈信息。-q选项只是让GDB启动时不要复印版本信息,防止视觉干扰。
编译一下,须要加上-g选项:
gcc -g siggdb.c -o siggdb运行,结果如右图:
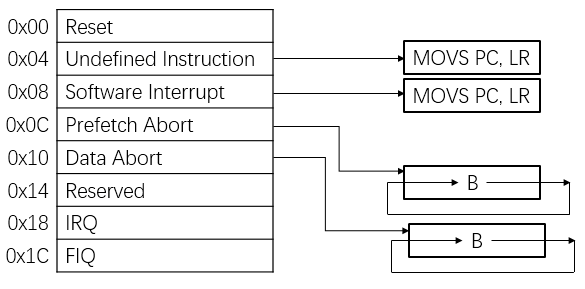
注意:此类方式只能在测试环境中使用,且要确保GDB可以正常使用。生产环境中不要使用!
6.libSegFault.so
不仅前面提及的几种方法外,虽然glibc也早已很贴心地提供了一种问题定位的方案:libSegFault.so
libSegFault.so是glibc提供的一个动态链接库qq for linux,用于捕捉程序运行异常并记录调用栈等调试信息。
它的实现原理和前面提及的第4种方式是一样的,即通过signalcapture的方法,程序发生异常时,在讯号处理函数中记录调试信息。
使用时,先确定系统中是否存在这个动态链接库。在我的系统中,有那么几个:
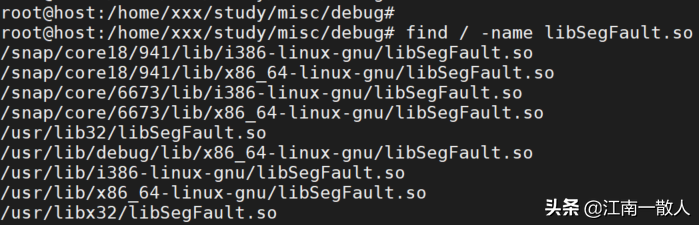
按照自己的实际情况,选择一个使用。例如我的测试环境是x64的,我选择使用:
/usr/lib/x86_64-linux-gnu/libSegFault.so之后借助环境变量LD_PRELOAD,在测试程序运行前,把libSegFault.so链接进来。
LD_PRELOAD=/usr/lib/debug/lib/x86_64-linux-gnu/libSegFault.so ./myapp仍以本文第一个测试程序为例:
编译:
gcc -rdynamic segfault.c -o segfault运行:
LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libSegFault.so ./segfault测试程序触发段错误后,libSegFault.so中的讯号处理函数会把寄存器、调用栈、内存映射全部dump下来。结果如右图(信息太多,分成了两张图片):
libSegFault.so运行结果
libSegFault.so运行结果(续)
libSegFault.so默认只捕捉SIGSEGV,可以通过设置环境变量SEGFAULT_SIGNALS指定要捕捉的讯号,如:
export SEGFAULT_SIGNALS="all" # "all" signals
export SEGFAULT_SIGNALS="segv bus abrt " #SIGSEGV, SIGBUS and SIGABRT
环境变量SEGFAULT_USE_ALTSTACK可以指定是否让讯号处理函数使用独立的栈,这在程序发送栈溢出时会很有用。
export SEGFAULT_USE_ALTSTACK=1libSegFault.so默认把调试信息输出到stderr,可以通过设置环境变量SEGFAULT_OUTPUT_NAMElinux视频,指定调试信息记录到一个文件中。诸如:
export SEGFAULT_OUTPUT_NAME="./debug.log"据悉,为了便捷用户使用,好多系统中还提供了一个名为catchsegv的脚本:
catchsegv ./segfault其疗效与通过LD_PRELOAD加载libSegFault.so是相同的:
7.Valgrind
Valgrind是一个很强悍的工具集,它可以测量显存泄漏、栈溢出、非法显存访问等多种显存相关的错误,还可以对程序进行性能分析、生成函数调用关系图、统计Cache命中率、监测多线程竞争等,是程序调试的神器。
Valgrind功能十分强悍,但文章篇幅有限,不对其展开讨论,后续会更新文章专门讲解它的各类功能,感兴趣的同学可以右上角关注一下。
下边演示用Valgrind检查示例程序的显存访问错误:
编译时加上-g选项:
gcc -g segfault.c -o segfault之后用Valgrind启动示例程序:
valgrind --tool=memcheck --leak-check=yes -v --leak-check=full --show-reachable=yes ./segfault显示数据较多,仅截取感兴趣的部份信息,如右图所示:
Valgrind成功测量出地址0x12345678既不是栈地址,也不是malloc分配的动态显存。而且它也会把调用栈信息dump下来。
Valgrind即使在检查显存相关的错误时十分强悍,并且它有一个致命的缺点,就是慢。据统计,通过Valgrind运行程序时,速率会增加10倍。这在调试小型项目时,尤其是对实时性十分敏感的程序,是难以接受的。
不过,我们还有一个更好的选择—AddressSanitizer。
8.AddressSanitizer
AddressSanitizer最初是Google开发的一个测量多种显存相关问题的工具,AddressSanitizer如今早已集成到GCC和LLVM中。它最大的特征是:
本文只简单演示用AddressSanitizer检查示例程序中的显存访问错误,后续会专门更新文章详尽讲解它的各类功能,感兴趣的同学可以关注一下。
AddressSanitizer的使用方式也十分简单,只须要在编译时加上相应的编译选项,之后正常运行程序即可。
这儿,我只使用最简单的一个编译选项-fsanitize=address开启AddressSanitizer功能。
gcc -g -fsanitize=address segfault.c -o segfault之后正常运行即可,截图如右图:
9.dmesg+objdump
有时,可能因为各类缘由,以上几种方式都不适用,例如程序中难以添加调试信息、程序难以重新编译、没有GDB和Valgrind等调试工具等。
这些情况下,调试上去,会相对比较困难一些,但也并不是完全不可能。
大多数情况下,程序发生segmentationfault而异常退出时,会在系统日志中记录一些信息,可以用dmesg查看:
可以从中得到触发异常的指令地址和被访问的显存地址,之后借助系统中现有的一些工具进行调试,如借助objdump对可执行文件进行反汇编,之后从汇编代码入手进行剖析,限于篇幅,不再展开讨论。
Linux下有好多特别有用的工具,如binutils工具集(objdump、nm、readelf等)、strace等,熟悉并善用这种工具,会事半功倍。
结语
本文简单介绍了段错误的常用的9种调试方法,其中好多方式都是值得深入阐述的。
例如signalcapture、Valgrind、AddressSanitizer、GDB等,都有好多更为高阶的使用方法,但限于篇幅,未能展开讲解,后续会更新相关文章进一步深入讲解。
不仅文中介绍的9中方式外,还有其它一些相像或衍生的方式,文中并未提到,欢迎童鞋们留言补充,互相学习!
本文是程序调试系列专题的第六篇。本系列专题致力介绍一些高阶调试方法、调试器的工作原理以及常见问题的定位方式和思路等内容。
其它已更新内容:
GDB动态复印:让你随时随地printf,不需更改代码,不需重新编译
调试引入的不确定性:必现的BUG神秘消失,断点改变代码执行逻辑
Linux调试方法:GDB自定义命令,按需订制适宜自己的调试工具
C语言:当GDB遇见复杂数据结构,两分钟带你把握四个高效调试方法
C语言:GDB调试时遇见宏定义如何办?一个小方法帮你一秒钟搞定

若对文中内容有疑惑,欢迎留言讨论,对本系列专题有任何建议也欢迎提出!
原创不易,别忘了转发点赞,把知识分享给志同道合的同学,感谢!
对编译器、OS内核、性能调优、虚拟化等技术感兴趣的童鞋,欢迎右上角关注!





